关注我博客的朋友知道我之前写过一篇图库的内容采集建设方法,另外还有一个就是问答的建设方案,其中也是基于采集内容的再处理建设(未来将分享给大家),这里说到的采集,就牵扯到了内容的来源构建上。
我原本的计划是将各种不同的页面采集过来,然后进行处理,简单的流程是:
采集规则设定——标签库设定——采集内容标题——比对数据库——无数据则采集此问题——采集同页面某回答——搜索此问题——各页面随机抽取回答——归纳为一个问答页——审核或删除某回答——根据问题与答案词组匹配标签库自动生成标签——审核显示
这里有几个实现难题:
1)流程过于复杂,基于现有的采集程序,无法实现需求;
2)程序开发周期强大,复杂流程与数据库的处理,开发工作量和难度都不小;
3)基于长期优化维护的成本;
其实上面那个是我一个比较理想化的seo内容采集的流程,相对而言,任何采集程序都无法如此智能的进行采集,除非是开发出强大的诸如搜索引擎的索引机制,这是一个高专业的领域。

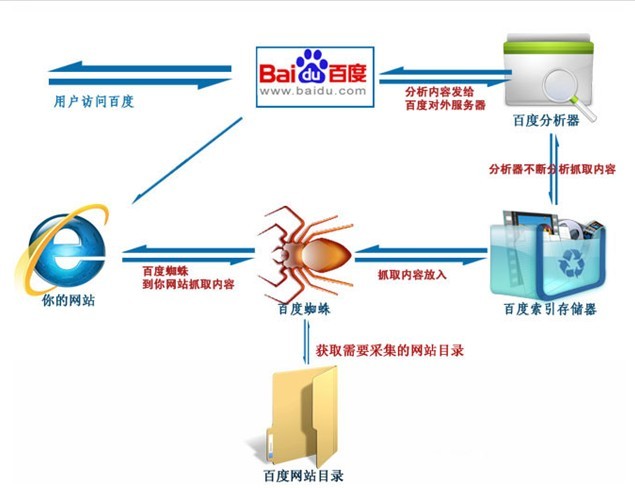
百度抓取原理和采集程序部分雷同
另外,其实我在当初的筹划中,有一个很理想化的状态,那就是采集大量的内容页面,生成大量的标签页面,来进行seo长尾词的排名实现与用户导航,但其实这里也很不现实(未来几天将和大家分享就标签页面这块建设的领悟,当然,有兴趣的朋友也可以看看我之前分享的:小说内容建设方法之标签聚合页面玩法),因为标签的排名作用已经弱化了,我们在搜索引擎中很少看到标签存在的影子。而且我们之前计划的是,建设150万左右的页面,标签页面占比10%,也就是需要采集130万左右的数据,这些数据需要配备大量的词汇,标签多达15万个,但我通过托词发现,15万个标签词的拓展,其实并没那么容易,大量工具产生的词汇,其实很多内容,并不适合拿来做标签,人工筛选又将带来大量的工作量。这是基于工作流程与实现逻辑而产生的问题。
那么问题来了,如此复杂的流程,既然不能实现,那应该怎么办?
这里要说下,当下有很多的采集程序,有实力的企业都会定制自己的内容采集与处理方案,但最流行的无疑就是利用火车头等常规采集工具了(将在后期和大家分享“数据采集工具的原理与现有采集工具的功能分析,敬请期待),大部分的采集工具都是基于目标源的采集,比如我采集某个页面的内容,自动去除某些无效元素,提取文本目标内容,大部分为文字和图片板块的采集,需要去除内外链。
火车头的采集也是基于此基础的升华,它也是基于目标网址的采集与筛选机制。
那么,基于此,我将上面的流程优化为:
采集规则设定——标签库设定——采集目标网址内容——比对数据库——已采集网址去除——确定采集——写入数据库——再次采集——同标题页面内容写入同数据库表——多问答形成——审核或删除某回答——根据问题与答案词组匹配自动生成标签——审核显示
这个流程还不算是最终版本,但相对程序来说已经简单不少,甚至火车头都能直接使用,无需二次开发,不过,具体还需我对火车头功能更熟悉后才能敲定,很多东西还是需要不断学习,最近感悟很深的是,在深圳的互联网环境下,以前错过了很多学习的机会,以至于现在要重新去拾起以前错过的成长机会,是幸运也是不幸。哆嗦完毕,只是希望将自己的这段成长经历分享给朋友们,未来大家一起见证奇迹的发生~!~。


